This blog post is written by AI CDT student, Matt Clifford
At the end of October ’23, I attended CIKM in Birmingham to present our conference paper. The conference was spread across 3 days with multiple parallel tracks on each day focusing on specific topic areas. CIKM is a medium size conference, which was a good balance between being able to meet many lots of researchers but at the same time not being overwhelmingly big that you feel less connected and integrated within the conference. CIKM spans many topics surrounding data science/mining, AI, ML, graph learning, recommendation systems, ranking systems.
This was my first time visiting Birmingham, dubbed by some the “Venice of the North”. Despite definitely not being in the north and resembling very little of Venice (according to some venetians at the conference), I was overall very impressed with Birmingham. It has a much friendlier hustle and bustle compared to bigger cities in the UK, and the mixture of grand Victorian buildings interspersed with contemporary and art-deco architecture makes for an interesting and welcoming cityscape.


Our Paper
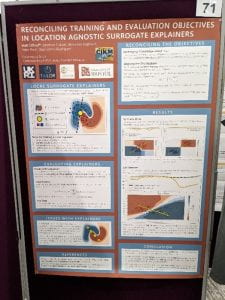
Our work focuses on explainable AI, which I helps people to get an idea the inner workings of a highly complicated AI system. In our paper we investigate one of the most popular explainable AI methods called LIME. We discover situations where AI explanation systems like LIME become unfaithful, providing the potential to misinform users. In addition to this, we illustrate a simple method to make an AI explanation system like LIME more faithful.
This is important because many users take the explanations provided from off-the-shelf methods, such as LIME, as being reliable. We discover that the faithfulness of AI explanation systems can vary drastically depending on where and what a user chooses to explain. From this, we urge users to understand whether an AI explanation system is likely to be faithful or not. We also empower users to construct more faithful AI explanation systems with our proposed change to the LIME algorithm.
You can read the details of our work in our paper https://dl.acm.org/doi/10.1145/3583780.3615284
Interesting Papers
At the conference there was lots of interesting work being presented. Below I’ll point towards some of the papers which stood out most to me from a variety of topic areas.
Fairness
- “Fairness through Aleatoric Uncertainty” – focus on improving model fairness in areas of aleatoric uncertainty where it is not possible to increase the model utility so there is a less of a fairness/utility tradeoff – https://dl.acm.org/doi/10.1145/3583780.3614875
- “Predictive Uncertainty-based Bias Mitigation in Ranking” – improve bias in ranking priority by reshuffling results based on their uncertainty of rank position – https://dl.acm.org/doi/abs/10.1145/3583780.3615011
Explainabilty
- “Deep Integrated Explanations” – Feature contribution maps for vision models – https://dl.acm.org/doi/abs/10.1145/3583780.3614836
Counterfactuals
- “Flexible and Robust Counterfactual Explanations with Minimal Satisfiable Perturbations” – https://dl.acm.org/doi/10.1145/3583780.3614885
- “CounterNet: End-to-End Training of Prediction Aware Counterfactual Explanations” – https://dl.acm.org/doi/abs/10.1145/3580305.3599290
Healthcare
- “Continually-Adaptive Representation Learning Framework for Time-Sensitive Healthcare Applications” – https://dl.acm.org/doi/10.1145/3583780.3615464
Data Validity
- “Automatic and Precise Data Validation for Machine Learning” – https://dl.acm.org/doi/pdf/10.1145/3583780.3614786
Cluster package in python
A group that were at the conference maintain a python package which neatly contains many state-of-the-art clustering algorithms. Here is the link to the GitHub https://github.com/collinleiber/ClustPy . Hopefully some people find it useful!