This blog post is written by lecturer in Computer Science, Dr Edwin Simpson
In November I was lucky enough to attend NeurIPS 2022 in person in New Orleans, and take part as a co-organiser of InterNLP, our second interactive learning for NLP workshop. I had many interesting discussions around posters, talks and coffee breaks and took loads of photos of posters. It was hard to write up my highlights and without the post becoming endlessly long, so here is my attempt to pick out a handful of papers that caught my eye and tell you a little bit about how our workshop unfolded.
Main Conference
One topic generating a lot of buzz was in-context learning, where language models learn to perform new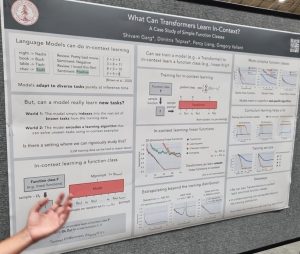 tasks without updating their weights from examples given in the model’s input prompt. Models like GPT3 can perform in-context learning from small numbers of examples. Garg et al. presented an interesting paper that triez to understand what classes of functions can be learned in this way [1]. They were able to train Transformers that learn function classes including linear functions and two-layer neural networks.
tasks without updating their weights from examples given in the model’s input prompt. Models like GPT3 can perform in-context learning from small numbers of examples. Garg et al. presented an interesting paper that triez to understand what classes of functions can be learned in this way [1]. They were able to train Transformers that learn function classes including linear functions and two-layer neural networks.

However, for few-shot learning, in-context learning may not be the best solution: Liu et al. [2] showed that fine-tuning a model by introducing a small number of additional weights can be cheaper and produce more accurate models.
Another interesting NLP paper from Jian, Gao and Vosoughi [3] learns sentence embeddings usingimage and audio data alongside a text training set. The method works by creating pairs of images (or audio) using data augmentation, which are then embedded and fed through a BERT-like transformer to provide additional data for contrastive learning. This is especially useful for low-resource languages and domains, and it is really interesting that we can learn from different modalities without any parallel examples.
Vosoughi [3] learns sentence embeddings usingimage and audio data alongside a text training set. The method works by creating pairs of images (or audio) using data augmentation, which are then embedded and fed through a BERT-like transformer to provide additional data for contrastive learning. This is especially useful for low-resource languages and domains, and it is really interesting that we can learn from different modalities without any parallel examples.
 Many machine learning researchers are concerned with models that produce well-calibrated probabilities, but what difference does calibration make to end users? Vodrahalli, Gerstenberg and Zou [4] investigated a binary prediction task in which a classifier provides advice ta user, along with its confidence. They found that exaggerating the model’s confidence led the user to perform better. So, the classifier was uncalibrated and had higher training loss but the complete human-AI system was more effective, which shows how important it is for ML researchers to consider real-world use cases for their models.
Many machine learning researchers are concerned with models that produce well-calibrated probabilities, but what difference does calibration make to end users? Vodrahalli, Gerstenberg and Zou [4] investigated a binary prediction task in which a classifier provides advice ta user, along with its confidence. They found that exaggerating the model’s confidence led the user to perform better. So, the classifier was uncalibrated and had higher training loss but the complete human-AI system was more effective, which shows how important it is for ML researchers to consider real-world use cases for their models.
Sticking with the topic of uncertainty, Bayesian deep learning aims to quantify uncertainty in complex neural network models, but is challenging to apply as it is difficult to specify a suitable prior distribution. Ideally, we’d specify a prior over the functions that the network encodes, rather than over individual network weights. Tran et al. [4] introduce a method for setting functional priors in Bayesian neural networks, by aligning them with Gaussian processes. It will be interesting to try out their approach in some deep learning applications where quantifying uncertainty is important.
deep learning aims to quantify uncertainty in complex neural network models, but is challenging to apply as it is difficult to specify a suitable prior distribution. Ideally, we’d specify a prior over the functions that the network encodes, rather than over individual network weights. Tran et al. [4] introduce a method for setting functional priors in Bayesian neural networks, by aligning them with Gaussian processes. It will be interesting to try out their approach in some deep learning applications where quantifying uncertainty is important.
At the poster sessions, I also enjoyed learning about the wide range of new benchmarks and datasets that will enable lots of exciting future work. For example, one that relates to my own work that I’d like to make use of is BIGBIO [5], which makes a number of biomedical NLP datasets more accessible and will hopefully to more reproducible results.
Juho Kim, who is associate professor at Korea Advanced Institute of Science and Technology (KAIST), gave a keynote on his vision of Interaction-Centric AI. He called on AI researchers to move beyond data-centric or model-centric research by rethinking the complete AI research process around the user experience of AI. Juho’s talk gave examples of how an interaction-centric approach may affect the way we evaluate models, which cases we focus on when trying to improve accuracy, how to incentivise users to engage with AI, and several other aspects of interaction-centric AI that his lab has been working on. He demonstrated Stylette, a tool that lets you use natural language to change the appearance of a website. The keynote ended with a call to action for AI researchers to rethink performance metrics, the design process and collaboration, particularly with HCI researchers.
Geoff Hinton appeared remotely from home to present the Forward-Forward algorithm, a method for training neural networks without backpropagation that could give insights into how learning in the cortex takes place. His experiments showed some promising early results, and in the Q&A Geoff talked about coding the experiments himself. A preliminary arXiv paper is now out [6].
1. Garg et al., What Can Transformers Learn In-Context? A Case Study of Simple Function Classes, https://arxiv.org/abs/2208.01066
2. Liu et al., Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, https://arxiv.org/abs/2205.05638
3. Jian, Gao and Vosoughi, Non-Linguistic Supervision for Contrastive Learning of Sentence Embeddings, https://arxiv.org/pdf/2209.09433.pdf
4. Vodrahalli, Gerstenberg and Zou, Uncalibrated Models Can Improve Human-AI Collaboration, https://arxiv.org/abs/2202.05983
5. Fries et al., BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing, https://arxiv.org/abs/2206.15076
6. Hinton, The Forward-Forward Algorithm: Some Preliminary Investigations, https://arxiv.org/abs/2212.13345
InterNLP Workshop
2022 was our second edition of the InterNLP workshop, and we were very happy that the community grew, this year with 20 accepted papers and a chance to meet in person! Some of the videos are on youtube at https://www.youtube.com/@InterNLP. Others will hopefully be available soon on the NeurIPS archives
The programme was packed with impressive invited talks from Karthik Narasimhan (Princeton), John Langford (Microsoft), Dan Weld (UWashington), Anca Dragan (UCBerkeley) and Aida Nematzadeh (DeepMind). To pick out just a couple, Karthik presented recent work on semantic supervision [1] for  few-shot generalization and personalization, which learns from semantic descriptions of classes, providing a way for instruct models through text. Anca Dragan talked about interactive agents that go beyond following instructions about how exactly to perform a task, to inferring the user’s goals, preferences,
few-shot generalization and personalization, which learns from semantic descriptions of classes, providing a way for instruct models through text. Anca Dragan talked about interactive agents that go beyond following instructions about how exactly to perform a task, to inferring the user’s goals, preferences,  and constraints. She emphasized that the way people refer to desired actions provides important information about their preferences, and therefore we can infer, from a user’s language, reward functions that reflect their preferences. Aida Nematzadeh compared self-supervised pretraining to language learning in childhood, which involves interacting with other people. Her talk focused on the evaluation of neural representations, and she called for real-world evaluations, strong baselines and probing to provide a much more thorough way of uncovering the strengths and weaknesses of pretrained models.
and constraints. She emphasized that the way people refer to desired actions provides important information about their preferences, and therefore we can infer, from a user’s language, reward functions that reflect their preferences. Aida Nematzadeh compared self-supervised pretraining to language learning in childhood, which involves interacting with other people. Her talk focused on the evaluation of neural representations, and she called for real-world evaluations, strong baselines and probing to provide a much more thorough way of uncovering the strengths and weaknesses of pretrained models.
The contributed talks and posters showcased a wide range of work from human-in-the-loop learning  techniques to software libraries and benchmark datasets. For example, PyTAIL [2] is a Python library for active learning that collects new labelling rules and customizes lexicons as well as collecting labels. Mohanty et al. [3] developed the IGLU challenge, in which an agent has to perform tasks by following natural language instructions; their presentation at InterNLP explained how they collected the data. The RL4M library [4] provides a way to optimize language generation models using reinforcement learning, as a way to adapt to human preferences; the paper [4] also presents a benchmark, GRUE, for evaluating RL methods for language generation. Majumder and McAuley [5] investigate the use of explanations to debias NLP models while maintaining a good trade-off between predictive performance and bias mitigation.
techniques to software libraries and benchmark datasets. For example, PyTAIL [2] is a Python library for active learning that collects new labelling rules and customizes lexicons as well as collecting labels. Mohanty et al. [3] developed the IGLU challenge, in which an agent has to perform tasks by following natural language instructions; their presentation at InterNLP explained how they collected the data. The RL4M library [4] provides a way to optimize language generation models using reinforcement learning, as a way to adapt to human preferences; the paper [4] also presents a benchmark, GRUE, for evaluating RL methods for language generation. Majumder and McAuley [5] investigate the use of explanations to debias NLP models while maintaining a good trade-off between predictive performance and bias mitigation.


At the end of the day, I got to ask a lot of questions to some very smart people during our panel discussion – thanks to John Langford, Karthik Narasimhan, Aida Nematzadeh, and Alane Suhr for taking part, and thanks to the audience for some great interactions too. The wide-ranging discussion touched on the evaluation of interactive systems (how to use static data for evaluation, evaluating how well models adapt to user input), working with researchers and users from other fields, different forms of interaction besides language, and challenges that are specific to interactive NLP.
discussion – thanks to John Langford, Karthik Narasimhan, Aida Nematzadeh, and Alane Suhr for taking part, and thanks to the audience for some great interactions too. The wide-ranging discussion touched on the evaluation of interactive systems (how to use static data for evaluation, evaluating how well models adapt to user input), working with researchers and users from other fields, different forms of interaction besides language, and challenges that are specific to interactive NLP.
We plan to be back at a future conference (not sure which one yet!) for the next iteration of InterNLP. Large language models and in-context learning are clearly revolutionizing this space in some ways, but I’m convinced we still have a lot of work to do to design interactive machine learning systems that are accountable, reliable, and require fewer resources.
Thank you to Nguyễn Xuân Khánh for letting us include his InterNLP workshop photos.
1. Aggarwal, Deshpande and Narasimhan, SemSup-XC: Semantic Supervision for Zero and Few-shot Extreme Classification, https://arxiv.org/pdf/2301.11309.pdf
2. Mishra and Diesner, PyTAIL: Interactive and Incremental Learning of NLP Models with Human in the Loop for Online Data, https://internlp.github.io/documents/2022/papers/24.pdf
3. Mohanty et al., Collecting Interactive Multi-modal Datasets for Grounded Language Understanding, https://internlp.github.io/documents/2022/papers/17.pdf
4. Ramamurthy et al., Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization, https://arxiv.org/abs/2210.01241
5. Majumder and McAuley, InterFair: Debiasing with Natural Language Feedback for Fair Interpretable Predictions, https://arxiv.org/abs/2210.07440