
This review of the 3rd day of the BIAS event, ‘Responsible AI’, is written by CDT Student Emily Vosper.
Monday was met with a swift 9:30am start, made easier to digest with a talk on AI and Ethics, why all the fuss? By Toby Walsh. This talk, and subsequent discussion, covered the thought-provoking topic of fairness within AI. The main lesson considered whether we actually need new ethical principles to govern AI, or whether we can take inspiration from well-established areas, such as medicine. Medicine works by four key principles: Beneficence, non-maleficence, autonomy and justice and AI brings some new challenges to this framework. The new challenges include autonomy, decision making and culpability. Some interesting discussions were had around reproducing historical biases when using autonomous systems, for example within the justice system such as predictive policing or parole decision making (COMPAS).
The second talk of the day was given by Nirav Ajmeri and Pradeep MuruKannaiah on ethics in sociotechnical systems. They broke down the definition of ethics as distinguishing between right and wrong which is a complex problem full of ethical dilemmas. Such dilemmas include examples such as Les Miserables where the actor steals a loaf of bread, stealing is obviously bad, but the bread is being stollen to feed a child and therefore the notion of right and wrong becomes nontrivial. Nirav and Pradeep treated ethics as a multiagent concern and values were brought in as the building blocks of ethics. Using this values-based approach the notion of right and wrong could be more easily broken down in a domain context i.e. by discovering what the main values and social norms are for a certain domain rules can be drawn up to better understand how to reach a goal within that domain. After the talk there were some thought provoking discussions surrounding how to facilitate reasoning at both the individual and the societal level, and how to satisfy values such as privacy.
In the afternoon session, Kacper Sokol ran a practical machine learning explainability session where he introduced the concept of Surrogate Explainers – explainers that are not model specific and can therefore be used in many applications. The key takeaways are that such diagnostic tools only become explainers when their properties and outputs are well understood and that explainers are not monolithic entities – they are complex with many parameters and need to be tailer made or configured for the application in hand.
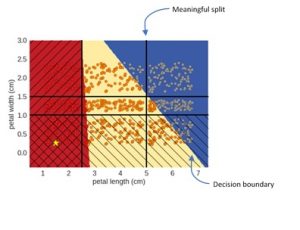
The practical involved trying to break the explainer. The idea was to move the meaningful splits of the explainer so that they were impure, i.e. they contain many different classes from the black box model predictions. Moving the splits means the explainer doesn’t capture the black box model as well, as a mixture of points from several class predictions have been introduced to the explainer. Based on these insights it would be possible to manipulate the explainer with very impure hyper rectangles. We found this was even more likely with the logistical regression model as it has diagonal decision boundaries, while the explainer has horizontal and vertical meaningful splits.